
גישה רביעית ואחרונה, בסדרה זו, למעבר חלק בין ארכיטקטורה ישנה לארכיטקטורה של דור מוצרים חדש. לכאורה, היא נראית כמו גישה טריוויאלית, אולם דווקא בגלל זה כדאי לשקול אותה רק לאחר בחינת האפשרויות האחרות. דברים שנראים פשוטים במבט ראשון עלולים להתברר כפשוטים פחות כאשר יורדים לפרטים.
אפשרות רביעית: אבולוציה של מודולים
תזכורת: הבעיה הבסיסית איתה התמודדנו היא, כיצד לעבור מארכיטקטורה א' לארכיטקטורה ב' תוך שמירה על רציפות יכולות השירות/המוצר. שלוש הגישות הקודמות שהצגנו חלקו מכנה משותף עיקרי, והוא: בנייה מסקראץ' של שלד הארכיטקטורה החדשה. רק לאחר שבנינו במלואו את הבסיס, בדקנו ודיבגנו אותו, המשכנו לשימוש בלוגיקה הישנה (אם כמערכת מלאה, חשופה או נסתרת, ואם כמודולים נפרדים) ווידאנו שהמערכת מספקת את השירותים המקוריים ללא ירידה ביכולות. מכאן ואילך, הוספנו פיצ'רים למערכת על פי הארכיטקטורה החדשה – גם פיצ'רים חדשים וגם כאלו ששוכתבו למערכת החדשה ומחליפים את קודמיהם הישנים.
לא תמיד המודל הזה ישרת אותנו. קיימים מקרים בהם לא נוכל, או לא נרצה, לבצע קפיצה למערכת חדשה, ונעדיף להתקדם לאט לאט מהמצב הקיים אל ארכיטקטורה טובה יותר. הסיבות לכך יכולות להיות מגוונות, ולא בהכרח טכנולוגיות בלבד. הנה כמה דוגמאות:
- כתיבת שלד ארכיטקטורה יארך זמן רב ואנו נדרשים לפתור חלק מהבעיות השורשיות באופן מיידי. במקרה כזה, ייתכן שאפילו מספר עקרונות בודדים (לעתים: אחד בלבד) מהארכיטקטורה החדשה יפתרו בעיות קשות, ויש חשיבות עליונה לאמץ אותם מהר ככל האפשר, ללא תלות בשאר הארכיטקטורה.
- חלקים בארכיטקטורה החדשה חייבים להיבחן לאורך זמן לפני שנחליט לאמץ אותם. אם שאר חלקי הארכיטקטורה תלויים בחלקים אלו, לא נרצה לבצע עבודה מלאה של בניית שלד שייתכן ובסופו של דבר לא יתאים לנו כלל. במקום זאת, נעדיף לממש חלקים מסויימים בשלב ראשון, לתת להם לעבוד זמן מה, ורק אז להמשיך בבניית שאר המערכת.
- הקצאת כח אדם לבניית ארכיטקטורה מלאה אינה אפשרית. לכל גוף תוכנה ישנם אילוצים רבים, והפניית מספר רב של מפתחים לטובת ארכיטקטורה חדשה לאורך זמן, עלולה לפגוע בשאר משימות הקבוצה. לכן, ייתכן וניתוב המשאבים יחולק באופן שונה, למשל, מעט מפתחים לאורך זמן ארוך, או מפתחים מדיסציפלינות שונות בכל פעם, בהתאם לשאר המשימות בכל רגע נתון. במקרה כזה יהיה קל יותר להתקדם בשלבים קטנים. בעיית כח האדם איננה חייבת להיות בקרב המפתחים בלבד. ביצוע של בדיקות סיסטם לשתי מערכות במקביל עלול לדרוש משאבי QA גבוהים, בעוד בדיקת מערכת אחת בכל פעם, גם אם חלים בה שינויים משמעותיים, מאפשר המשך בדיקות במשאבים דומים. אותו הדבר נכון גם להטמעה, ל-PreSale, ל-PostSale ולכל תחום אחר המושפע מכך.
במקרים כגון אלו, נעדיף לבצע אבולוציה הדרגתית של המערכת. בכל פעם נחליף רכיב מסויים (או מספר רכיבים קשורים) ונוודא כי המערכת ממשיכה לעבוד כמצופה. בדרך זו אנו מקבלים מעבר הדרגתי ובטוח בין הארכיטקטורה הישנה לחדשה.
גמישות מוצרית
מבחינה מוצרית, יש לנו כעת גמישות רבה יותר בהחלטה על גרסאות. אפשר להוציא גרסא חדשה על כל שינוי, אפשר להוציא גרסא רק בכל פעם שישנה הצטברות שינויים משמעותית, ואפשר להוציא גרסא רק בהתאם לפיצ'רים חדשים שנוספו במקביל לשינויים הארכיטקטוניים. את שינויי הארכיטקטורה עצמה ניתן לתעדף, ולהחליט מי מהם צריך להיכנס באופן מיידי, מי יכול להמתין להמשך, על מי מהם ניתן לוותר כליל במקרה של מחסור במשאבים, ומי מהם חייב להתבצע לפני הכנסה של פיצ'ר חדש כלשהו.
התקדמות בטוחה
התקדמות בדרך זו משתלבת היטב בגישת ה-TDD. אם עדיין אין לנו סט טסטים מתאים, נבנה כזה לפני כל שינוי. לאחר השינוי, נוכל לוודא שהטסטים ממשיכים לעבוד ללא שינוי, או – במקרה בו השינוי אמור להתבטא בהתנהגות – שהשינוי עונה לדרישות הטסט. מערכת אוטומטית של Regression Tests עם כלים של Continuous Delivery יאפשרו עבודה חלקה כך שבמקרה ששינוי בארכיטקטורה מתבטא במקום אחר במוצר, נוכל לתפוס את הבעיה ברגע שנוצרה, ולתקן אותה מיידית.
סיכונים אפשריים
למה לדחות למחר מה שאפשר לדחות למחרתיים?
למרות שכאמור, מדובר בגישה כמעט טריוויאלית – בגישה זו סיכונים וקשיים רבים מאוד. בראש וראשונה, הסיכון העיקרי: דחיית הארכיטקטורה בשלמותה לגרסא "9.99". כל עוד אנו נוקטים בגישה של שינויים מינוריים יחסית לאורך זמן, ניתן לומר בבטחון שמשימות דחופות אחרות ייכנסו בתעדוף גבוה יותר בכל שלב. לכן, קיים סיכוי גבוה שלעולם לא נשלים את בניית הארכיטקטורה במלואה, ונישאר רק עם חלקים ממנה. כמו שאני נוהג לומר בכל נושא: לא מדובר בהכרח בדבר רע. ייתכן בהחלט שההחלטה הנכונה תהיה לאמץ רק 50% מתכניות השינוי המוצעות, ולפתור בכך 95% מהבעיות הקיימות. אולם אם זו ההחלטה – יש לקבל אותה כהחלטה, ולא לגלות בדיעבד שנגררנו לשם בגלל הנסיבות.
כשיש יותר מעקפים מכבישים
סיכון גבוה אפילו יותר הוא, שנקבל מוצר שהוא שעטנז בין הארכיטקטורה הקודמת, הארכיטקטורה החדשה, ושאריות של טלאים שנוספו כדי לאפשר את השינוי הזה בשלבים קטנים. ככל שהארכיטקטורה הנוכחית בנויה נכון יותר ומורכבת מחלקים שהם Loosely Coupled, כך יהיה קל יותר לבצע בה החלפות מקומיות ללא תקורה מיותרת. אם, למשל, יש לנו מערכת שרצה על מחשב אחד אבל מבוזרת לתהליכים רבים – יהיה קל יחסית להוסיף שכבת תקשורת שמאפשרת ביזור של התהליכים על פני מחשבים שונים. אם היא לא בנויה מתהליכים אבל כל רכיב בנוי במודול משלו עם API סטנדרטי מול שאר המערכת, יהיה קשה יותר, אך עדיין אפשרי להפוך כל מודול לתהליך. אם כל הרכיבים יושבים באותו מודול תחת איזשהו Switch-Case, זה יהיה כבר "ניתוח" מסובך בהרבה. ואם הלוגיקה של כל רכיב כלל לא יושבת באותה יחידה אלא פזורה בין מודולים יחד עם קוד של עוד רכיבים… זה כנראה יהפוך למבצע מסובך כל כך, שספק רב אם זו הגישה הנכונה עבורו. במקרה כזה, כל שינוי ברכיב נתון ידרוש הרבה מאוד תקורה עבור אדפטציה.
למשל: אם נרצה לשנות "רק" את שכבת ה-DB, נצטרך לשנות את כל הקריאות אליה. אם הקריאות הקיימות מתבצעות בצורה מסודרת, דרך API סגור ומצומצם המשתמש ב-ORM נתון, זה יכול להיות קל יחסית כיוון שהשינוי יתבצע רק מתחת לשכבה זו. אולם אם המערכת הקיימת מבצעת קריאות ישירות ל-DB ממקומות רבים ושונים, וללא חוקיות ברורה, מדובר בתהליך כואב מאוד. כיוון שהרעיון הוא לבצע שינויים תחומים בגודל ובזמן, לא בהכרח נוכל לנצל את ההזדמנות הזו כדי להוציא את הקריאות הישנות ל-DB לחלוטין ולהחליף אותן בשכבת API מסודרת, למרות שכך היינו רוצים לראות את הארכיטקטורה בסופו של דבר. במקום זאת, אנו עלולים למצוא את עצמנו "תופרים" קריאות ל-DB כך שבכל מקום שהן אינן מתאימות עוד, נכניס שינוי קטן ומקומי שיפתור את זה.
סיימנו את שלב החלפת ה-DB בהצלחה? עכשיו נוכל להתקדם עוד צעד אחד. למשל, להחליף סוג מסויים של קריאות בסוג אחר, שינצל את ה-DB החדש שלנו ומנגנון האינדקסים המהיר שלו שבגללו בחרנו להחליף את הקודם. המשמעות היא לעבור על כל הקריאות ל-DB בקוד, לזהות את אלו שניתן להחליף בקלות ולבצע זאת. ואחר כך, אולי, לזהות עוד סוגי קריאות, שלא ניתן להחליף בקלות של קריאה-במקום-קריאה, אבל ניתן להחליף בסט של קריאות במקום קריאה בודדת, שיהיו טובות יותר מהגישה הקודמת. אם כן, יש לנו כבר שלושה דורות של שינויים:
- שינוי כל קריאה ל-DB הישן שאינה תואמת את החדש, כך שהיא תחזיר אותם ערכים
- שינוי כל קריאה מסוג "X" לקריאה מסוג "Y"
- שינוי כל קריאה מסוג "A" לרצף קריאות מסוג "B, C, D" ולוגיקה עליהן
וכך נמשיך וניצור עוד ועוד דורות של שינויים. בעצם, הארכיטקטורה המקורית שאליה שאפנו בכלל הגדירה הפרדה מוחלטת בין הלוגיקה לבין ה-DB! התכנית שאליה שאפנו היתה ליצור API סגור, שעובד מול ORM כלשהו, וכך יוצר הפרדה מוחלטת בין הלוגיקה לבין ה-Data. אבל הצורך לבצע שינוי מינורי בכל פעם, כך שהמערכת תמשיך לעבוד – השאירה אותנו עם המוני תיקונים, מעקפים וטלאים, כך שכאשר הגענו לשלב ה-API, כבר הוחלט לוותר על חלק מהשינויים כיוון שהם יקרים מאוד ופחות קריטיים למוצר. זוכרים את תמונת המחלפים מהפוסט המקורי? כן. על זה בדיוק אני מדבר. זה מה שקיבלנו.

זה לא אומר שלעולם אין להשתמש בגישה הזו. ההיפך הוא הנכון – בשל אילוצים רבים ב-Real World, זוהי גישה מקובלת מאוד, אולי המקובלת ביותר. מה שחשוב הוא להבין את הבעיות שבה על מנת לצפות אותן מראש ולהימנע מהן ככל האפשר.
שלב אחרי שלב
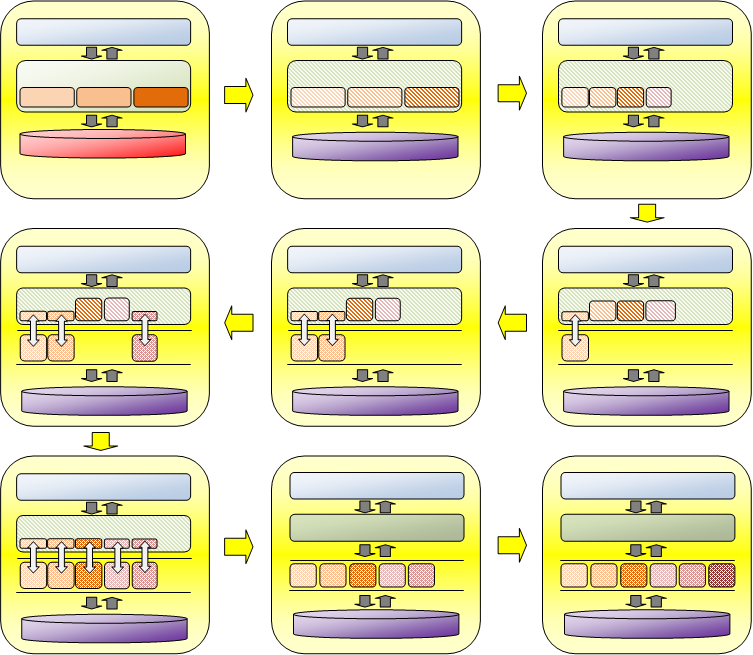
גם הפעם נדגים את הגישה באמצעות ה"מערכת לזיהוי שירים" שהצגנו בעבר. במערכת זו, ייתכן למשל רצף השינויים הבא:
- המערכת המקורית מכילה את בסיס הנתונים הישן ואת מנגנון ה-Analyzer יחד עם שלושת הפיצ'רים לשירים.
- נחליף DB, ויחד איתו נבצע את השינויים המתחייבים ברכיב ה-Analyzer ובכל אחד משלושת הפיצ'רים של השירים כך שיתאים ל-DB החדש.
- נוסיף את פיצ'ר #1 לסרטים. הוא צריך להיות תואם ל-DB החדש, אבל עדיין עובד במנגנון הישן של ה-Analyzer שמריץ ישירות את הפיצ'ר בהתאם לקריאת ה-API.
- נשכתב את פיצ'ר השירים #1 בצורה כזו: הלוגיקה העיקרית שלו תרוץ באופן עצמאי כמיקרו-שירות. כיוון שהמערכת עדיין אינה מכילה Dispatcher המנהל את הקריאות למיקרו-שירותים, נבנה שכבת לוגיקה דקה עבור פיצ'ר זה, שמופעלת ישירות בידי המנגנון הקיים (Analyzer) ואחראית לתפעל את הלוגיקה של הפיצ'ר כמיקרו-שירות.
- נבצע את אותו התהליך עבור פיצ'ר השירים #2.
- כעת נרצה להוסיף את פיצ'ר הסרטים השני. נכתוב גם אותו בדרך דומה, כמיקרו-שירות עצמאי עם שכבת הפעלה הנמצאת ב-Analyzer.
- נשכתב את הפיצ'רים שנותרו (פיצ'ר שירים #3, ופיצ'ר סרטים #1) כמיקרו שירותים.
- כעת, כאשר כל הפיצ'רים במערכת רצים כמיקרו שירותים, נבצע את השינוי המשמעותי ביותר בארכיטקטורה: נחליף את ה-Analyzer במנגנון ה-Dispatcher, שיתפעל מעכשיו באופן ישיר את חמשת המיקרו-שירותים במערכת.
- אם נרצה להוסיף כעת עוד פיצ'ר (פיצ'ר סרטים #3), נוסיף אותו פשוט כעוד מיקרו-שירות.
כך עברנו מן המערכת המקורית למערכת החדשה, בעזרת שינויים מינוריים ככל האפשר בכל פעם.
סיכום
מעבר "אבולוציוני" בין ארכיטקטורות הוא מעבר אותו מיישמים פעמים רבות, עקב אילוצים שאינם מאפשרים גישות יותר מתוחכמות לבעיה. ככל שהארכיטקטורה הקיימת טובה יותר, כך גם המעבר יהיה פשוט בהרבה; ארכיטקטורה הבנויה בצורה טובה מספיק, מאפשרת למעשה להסתפק בהחלפת חלקים קטנים יחסית בתוך המערכת בצורה נקיה, ולהישאר יציבה. כך ניתן להישאר לאורך שנים ללא שינוי רדיקלי במערכת ולשמור על יציבותה, כאשר רק בעיות נקודתיות נפתרות בכל פעם. במערכת שהצגנו, למשל, השינוי ב-DB והשינוי למבנה של מיקרו-שירותים הם שני שינויים נפרדים, וניתן לבצע אחד ללא השני, אם הוא פותר את הבעיות הקיימות בצורה טובה מספיק.
יתרונות
- אין צורך בשינוי משמעותי במצבת כוח האדם או בקצב ההתקדמות בצירים אחרים (פיצ'רים) במערכת
- אין צורך לאפשר לשתי מערכות לרוץ במקביל
- ניתן להחיל חלקים קריטיים בארכיטקטורה הנדרשת, תוך ויתור או דחיה של חלקים חשובים פחות
- ניתן לבחון עקרונות ארכיטקטוניים בצורה הדרגתית, מול פיצ'רים קיימים, לפני שמוקם שלד ארכיטקטורה כולל
- השינויים הארכיטקטוניים מנוהלים כמו כל שאר השינויים (פיצ'רים ובאגים), ולא כתהליך עצמאי העשוי לדרוש תכנון וניהול מסובכים יותר
חסרונות
- השינוי עלול להיגרר זמן רב בהרבה מהצפוי, ואף לא להסתיים לעולם
- במערכת שאינה מודולרית מספיק, תקורת הקוד הנדרשת כדי לאפשר מעבר "מקומי" בכל פעם עלולה להצטבר כך שהתוצר הסופי יהיה שונה מאוד מן הארכיטקטורה המקורית שתוכננה
- במערכות מסויימות, מסובך עד בלתי אפשרי לבצע שינויים "מקומיים", והדרך הנכונה לשנות אותן היא באמצעות כתיבה מחדש של הארכיטקטורה כולה
מתי זה יתאים
- כאשר המערכת הנוכחית ניתנת לחלוקה המאפשרת שינוי בחלקים ממנה בלבד
- כאשר הארכיטקטורה החדשה כוללת מספר שינויים, שכל אחד מהם בפני עצמו הוא בעל משמעות חשובה
- כאשר לא ניתן להקצות משאבים לטובת ניהול/פיתוח/בדיקה של מערכת חדשה לחלוטין ויש צורך לעשות זאת כחלק מתהליך הפיתוח הכולל
- כאשר לא ניתן להריץ מערכות במקביל וגם לא ניתן "לזרוק" את המערכת הישנה ולהחליף אותה בבת אחת
בהצלחה!