מספרים (מעולם לא בדקתי – המנדרינית שלי חלודה לגמרי) שבעולם הרפואה הסיני, הפציינט משלם לרופא רק כל עוד הוא בריא. ברגע שהאדם נזקק לשירותיו של הרופא בשל מחלה – הוא מפסיק לשלם לו. זה, כמובן, אינו אומר שהרופא מרוויח כסף סתם כך. תפקידו החשוב הוא להתוות את הדרך לחיים בריאים, ולסייע לפציינטים שלו להישאר בריאים ולא לחלות.
כארכיטקטים, או מפתחים, זהו בדיוק תפקידנו ביחס למערכת. הטיפול הטוב ביותר בכשל הוא הימנעות ממנו. ובכל זאת, בניית מערכת ללא תקלות היא משימה על גבול הבלתי אפשרי, ויותר מזה – המאמץ הנדרש לבניית מערכת כזו אינו עומד תמיד בהלימה למערכת עצמה. לכן, הטיפול בכשלים יהיה שונה בכל מערכת.
בפוסט הזה, אציג מספר קווים מנחים שיש לבחון בעת בניית מערכת. חלקם נוגעים לארכיטקטורה, וחלקם לרמות נמוכות יותר. בהמשך, אעלה מדי פעם פוסטים המתמקדים באופן נרחב יותר בתחומים השונים.

כשלים: איך לא?
התמודדות עם כשלים מורכבת ממניעתם ככל האפשר, מבניית מערכת המסוגלת להתגבר עליהם באופן "טבעי" או באמצעות הפעלת אמצעי התאוששות (אוטומטיים או ידניים), ומקבלת החלטה כיצד תפעל המערכת במקרה בו בכל זאת אירע כשל. תהליך לא פחות חשוב הוא, למידה מכשלים שאירעו על מנת לשפר את ההיערכות להם בגרסאות הבאות. כדי לעשות מעט סדר בדברים, הנה חמש נקודות עיקריות בנוגע לכשלים, להן חשוב לשים לב בעת תכנון מערכת:
- מניעת כשלים
- צמצום כשלים
- זיהוי כשלים
- התאוששות מכשלים
- התרעה על כשלים
בפוסט זה, אעבור בקווים כלליים על נקודות מנחות אלה.
מניעת כשלים
כאמור, הדרך הטובה ביותר להתגבר על כשלים היא למנוע אותם. ישנן נקודות רבות בהן ניתן להקדים תרופה למכה; אני מחלק אותן לשתי קבוצות שונות: תכנות ותכנון.
תכנות
כתיבת קוד נכון, ברמת הקידוד הנמוכה ביותר – ללא תלות בדיזיין ובארכיטקטורה – יכולה למנוע את מרבית הכשלים המיותרים ביותר, כאלו שללא הטיפול הנכון עלולים לגרום לקריסת כל המערכת בלי שום סיבה סבירה. הנה, למשל, מספר דוגמאות לקוד שיגרום לקריסת מערכת, שכל אחד נתקל בכמה מהן:
- פניה לקובץ שאינו קיים או ללא הרשאות מתאימות
- שאילתא למבנה נתונים המבקשת אלמנט ספציפי, כאשר האלמנט אינו נמצא או שהשאילתא מתאימה ליותר מאלמנט אחד
- נסיון לבצע פעולות על משתנים מטיפוס לא מתאים
- ואפילו… חישוב מתמטי שבנסיבות לא צפויות עלול לגרום חלוקה באפס.
כל אלו הן פעולות שקידוד נכון יימנע מהן: בדיקת הקובץ לפני הפניה; שאילתא המחזירה רשימה ולא אלמנט; וידוא טיפוס המשתנה; בדיקת ערך המכנה. אלו פעולות פשוטות, לפעמים פשוטות כל כך שנוטים לוותר עליהן.
במאמר מוסגר: ניתן, כמובן, לפתור את אותה הבעיה גם בעזרת תפיסת Exceptions. בחלק מן המקרים זה פתרון לא רע, בחלק מן המקרים זה הפתרון העדיף, ובחלק מן המקרים, זה יהיה חסר טעם. בכל מקרה, מבחינת ההימנעות מכשל, זה פחות משנה אם ביקשנו "רשות" או ביקשנו "סליחה". מתודולוגית השימוש ב-Exceptions היא נושא חשוב שאדון בו בפוסט נפרד.
תכנון
תכנון נכון של המערכת חשוב לא פחות להימנעות מכשלים בסיסיים. הנה עוד כמה דוגמאות לכשלים אפשריים:
- לא ניתן לכתוב לקובץ מפני שאין די שטח דיסק
- מערכת ההפעלה אינה מאפשרת הרצת תהליך נוסף
- זמן עיבוד של מנגנון מחזורי כלשהו אורך יותר מזמן המחזור
מובן שגם כשלים כאלו חשוב לזהות בטרם הפעולה או לתפוס את ה-Exception המתאים. ניתן גם להתגבר עליהם, לעתים בקלות. ובכל זאת, ניתן להימנע לחלוטין מכשלים מסוג זה בדרכים פשוטות של תכנון מערכת שונה: הקצאת שטח דיסק גדול יותר; הגדרה נכונה של הרשאות היוזר; שינוי זמן המחזור או בחירת חומרה חזקה יותר – כל אלו ימנעו את הכשל כך שלא יהיה צורך להיתקל בו כלל.
צמצום כשלים
גם אם נדאג שלא להיתקל בכשלים ככל האפשר, לא נוכל להימנע מכך לחלוטין. בעיות תקשורת, למשל, לא תמיד תהיינה בשליטתנו. ובכל זאת, לא כל בעיה חייבת להפוך לכשל מערכתי. נסיון תקשורת כושל, למשל, קל מאוד לצמצם באמצעות מספר קטן של פעולות Retry. זה לא יפתור את הבעיה אם אכן יש בעיה משמעותית, אבל זה בהחלט ימנע מבעיה רגעית להפוך לבעיה אקוטית. אם ניסינו לכתוב קובץ לספריה והיא לא קיימת – אפשר פשוט לייצר אותה ולנסות שוב. אם רשומה כלשהי אינה מופיעה במסד הנתונים – ניתן במקרים מסויימים לייצר אחת עם ערכי ברירת מחדל.
בדרך זו נוכל לצמצם מאוד את הבעיות ה"מערכתיות". הדוגמאות שמופיעות כאן דואגות לכך שפתרון מערכתי יידרש אך ורק לבעיה מערכתית. כל שאר הבעיות תיפתרנה בצורה מקומית – ברמת הפונקציה או המודול, ברמת הקידוד וללא תלות או השפעה על הדיזיין והארכיטקטורה (כמובן – יש לשים לב שהדברים אכן פתירים בדרך כזו. מספר Retries, למשל, עלול בתורו להתארך יותר מזמן ה-Timeout של פעולה אחרת, ובכך, במקום לפתור את הבעיה באופן מקומי, להפוך אותה לבעיה רחבה יותר).
זיהוי כשלים
מטרה
זיהוי הכשל ברגע שהוא קורה, הוא תנאי הכרחי כדי להתאושש ממנו. ברור למדי.
ובכן, בעצם… לא.
אבל זה שייך לסעיף הבא, "התאוששות". כאן אנחנו מדברים על זיהוי. זיהוי כשלים חשוב משתי סיבות. ראשית, ישנם כשלים, או מערכות, בהן מתחייב לזהות את הכשל על מנת שניתן יהיה לבצע פעולת התאוששות. דוגמא מוכרת לכך היא Watchdogs: אם נזהה שתהליך כלשהו, או מחשב כלשהו, אינם מגיבים, נוכל להפעיל מנגנון התאוששות, כמו הקמה של תהליך חדש, איתחול של המחשב, או הפעלת צופר אזעקה.
סיבה שניה בגללה חשוב לזהות כשלים – גם אם המערכת חסינה להם – היא, כמובן, לצורך מעקב, ניתוח ותכנון. לכן לא מספיק לעקוף את הכשל, וגם לא לדעת שהיה כשל "כלשהו". ככל שנדע יותר על הכשל, על המצבים הגורמים לו, על תדירות ההופעה שלו, על הסביבה, הקונפיגורציה ויחסי הגומלין במערכת בזמן הופעתו – יהיה קל יותר להתגבר עליו בהמשך, בין אם בצורה של ארכיטקטורה מתאימה ובין אם בצורה של פתרון מקומי. חשוב לזכור שגם כשל שהמערכת בנויה להתגבר עליו בקלות, עלול להפוך לקריטי אם התדירות שלו תגבר.
אמצעי
ישנן שתי דרכים עיקריות לזיהוי כשלים. דרך ראשונה — אותה מממשת כל מערכת — היא זיהוי פנימי של הכשל. למשל: חוסר אפשרות להקצות זכרון, לפנות לכתובת IP, לכתוב לדיסק. כשלים אלו יתגלו בידי המערכת עצמה והיא זו שתדווח עליהם.
מנגנון נוסף הוא מנגנון שאינו מופעל בעת הכשל בידי המערכת עצמה, אלא מחייב ניטור של המערכת. למשל: מחשב מסויים התנתק מהרשת; תהליך מסויים איננו מגיב; שטח הדיסק הפנוי קטן בצורה קיצונית. כשלים מסוג זה דורשים מנגנוני ניטור, כמו Watchdogs או Resource Monitoring. הניטור יכול להתבצע בידי רכיבים נוספים במערכת עצמה, או באמצעות כלים חיצוניים למערכת, בין אם כלי מדף או כאלו שנכתבו בידי החברה ככלי נפרד.
התאוששות
ישנם מנגנוני התאוששות שונים, אשר ניתן, בצורה גסה, לחלק לשלוש גישות. פתרון, שמתגבר על הבעיה המקורית; מעקף, שמאפשר המשך עבודה גם ללא פתרון ה-Root Cause, ותכנון טולרנטי: בניית ארכיטקטורה אשר מתמודדת באופן טבעי עם הכשל. ישנה גם גישה רביעית, הנדרשת בעיקר בסוג מסויים של מערכות: השבתה — או, למעשה, אי-התאוששות.
רוטינת פתרון
מערכת שמזהה במהירות כשלים, תוכל להפעיל במהירות מנגנון התאוששות. כבר הזכרנו דוגמאות כמו הקמת תהליכים חדשים או אתחול של מחשבים. דוגמאות אחרות יכולות להיות, למשל:
- הפיכת אחד משרתי ה-Slave של בסיס נתונים לשרת ה-Master
- הפניית התעבורה דרך מסלול ראוטינג שונה
- שימוש באמצעי אחסון מידע חליפי
- תעדוף שונה של תעבורה
- חסימת שירותים לא קריטיים
העקרון הוא פשוט: מדובר בכשל שצפינו מראש את קיומו האפשרי, הגדרנו מנגנון המסוגל לזהות אותו באופן מיידי, והכנו מראש פתרון למקרה כזה. הפתרון יכול להיות אוטומטי, אך הוא יכול להיות גם פתרון המנוהל בידי אנשי התמיכה. כמובן, לכל אחת מהאפשרויות קיימים יתרונות וחסרונות. ישנם מקרים בהם קל יחסית להגדיר פתרון באופן אוטומטי, ולחסוך בכך את הזמן הנדרש עד להתערבות אנושית, להקטין את מערך התחזוקה, ולמנוע מבוכה מול לקוחות. מאידך, במקרים מסויימים, פשוט יותר לדאוג שאדם המכיר את המערכת יבין בדיוק מה הבעיה ויפתור אותה, מאשר לבנות מערכת תוכנה שתעשה זאת באופן מושלם.
מעקף בעיות
לא את כל הכשלים נוכל לצפות מראש. כשלים רבים עלולים להיות חמקמקים ולא ברורים לחלוטין. לעתים, גם אם בעיות במערכת תמשכנה להופיע ברציפות, יהיה קשה לזהות מה בדיוק מקורן ולגזור מכך את הפתרון המתאים. ובכל זאת, גם לבעיות מסוג זה, ניתן פעמים רבות לייצר "מעקף" (Workaround) אשר ידאג שהמערכת תמשיך לתפקד גם ללא הבנה של מקור הבעיה — ה-Root Cause. במקרים כאלו, ניתן לנסות ולזהות מאפיינים אשר מתקשרים בסבירות גבוהה לכשל, גם אם לא מדובר בקשר ודאי או בכזה שיש לנו הסבר לגביו. אם נזהה מצב כזה, נוכל לנסות ולהפעיל "רוטינת פתרון" (אוטומטית או אנושית, בדיוק כמו בסעיף הקודם), כך שהמערכת תמשיך לתפקד כראוי. הנה כמה דוגמאות למצבים כאלה:
- עומס יתר. מצב שבו משאבים — כמו זכרון, שטח דיסק, כוח עיבוד, ערוץ תקשורת — נמצאים בעומס יחסי, עלול לגרום לבעיות. לא תמיד נוכל לזהות בוודאות את הבעיה הקונקרטית, אך ייתכן שנוכל בכל זאת לראות כי כשלים מסויימים, זהים או שונים, מתרחשים תחת עומס. במקרה כזה, ניתן לפתור את הבעיה בכך שנוריד את רמת העומס במערכת. בין אם באמצעות ניטור העומס והגדלת המשאבים ברגע שעלינו מעל לסף כלשהו (למשל, הקמה של עוד שרתים וירטואליים או הפניה של משימות למשאבים אחרים) ובין אם באמצעות הקטנת נפח העבודה (למשל, הורדת קצב הביצוע של מנועים עצמאיים או אי קבלת בקשות חדשות של שרתי SaaS).
- ריסטארט. זהו הפתרון האוטומטי שלנו לבעיות רבות בחיי היום-יום, ובכל זאת אפשר לקבל צמרמורת רק מהמחשבה שזה יהיה פתרון במערכת שבנינו. המציאות היא אי שם באמצע: מערכת שתבצע ריסטארט אוטומטי כדי לחזור לתפקוד תקין היא לא בהכרח פאר היצירה הארכיטקטוני, אבל מצד שני – אם זה עושה את העבודה, אז צמרמורת היא לא טיעון-שכנגד חזק מספיק. תארו לעצמכם, למשל, מערכת מבוזרת בת כמה שנים, שעברה אבולוציה משמעותית מאוד מאז שהוגדרה ונכתבה לראשונה, ובה כל שרת הופך לפחות אפקטיבי לאחר שבוע של עבודה רציפה. האפשרויות הן לבצע ריסטארט לכל שרת לאחר שבוע, תוך וידוא ששאר השרתים ממשיכים לעבוד באותו הזמן ולספק את השירות, או – להקים כח משימה שיחקור לעומק את מהות הבעיות, יזהה אותן במלואן ובוודאות, וישכתב את הקוד כך שהכשל ייפתר בצורה מהותית. עם כל אי הנוחות שב"פתרון" מסוג זה, כנראה שבמקרים כאלו זהו הפתרון הנכון.
- ביצוע מחדש. במערכת בה כל משימה עוברת Workflow מורכב, ייתכן שבחלק מהמקרים ישנן משימות שאינן מגיעות לשלב הסיום. דרך אחת היא לעקוב אחר המשימות לאורך השלבים השונים, ולזהות בדיוק את הכשל – באיזה רכיב, באיזה סוג משימות וכן הלאה. פתרון אחר, פשוט יותר, יכול לקבוע לכל משימה זמן סביר לביצוע, ואם עבר ה-Timeout מרגע ייצור המשימה, והיא עדיין לא הגיעה לכדי סיום – נבטל אותה ונייצר משימה אחרת במקומה.
דיון מעניין בשאלה מתי נכון להתמקד בזיהוי ופתרון אמיתי של ה-root cause ומתי להעדיף פתרון שהוא workaround מופיע כאן: "ארכיטקטורה: האם לנסות שוב?" בבלוג של ליאור בר-און.
ארכיטקטורה טולרנטית
בסעיף הראשון הצענו לפתור בעיות אותן אנו מזהים; בסעיף השני, הצענו דרך לפתור בעיות אותן איננו מזהים. דרך שלישית היא לבנות מערכת שבה הבעיות אינן דורשות "פתרון", כיוון שהן כלל לא תהפוכנה לכשל מערכתי. נניח, למשל, מערכת הפרושה על פני מספר איזורים, מתנהלת מול בסיס נתונים, ומעבירה משימות בין תהליכים שונים בעזרת Message Queue. הנה מספר כשלים שייתכנו במערכת כזו:
- התהליך (או השירות) שמנהל את ה-Message Queue נפל, וכך הלכו לאיבוד כל המסרים שהיו בזכרון וטרם טופלו.
- בעיית תקשורת גורמת לכך שלא לכל האיזורים ישנה גישה לבסיס הנתונים.
- תהליך מסויים התחיל לבצע משימה, וקרס, או נתקע.
ישנן דרכים רבות להתגבר על בעיות כאלו כאשר הן מתגלות, אבל ישנן גם דרכים שהופכות את הכשלים הללו ל"שקופים", כך שאין צורך במנגנון מיוחד להתאוששות – המנגנון הבסיסי נוצר בדרך החסינה לכשלים מסוג זה. למשל:
- במקום לנהל Message Queue במבנה נתונים היושב בזכרון של תהליך (כלומר, ב-RAM), נשתמש בטבלה או Collection של בסיס נתונים כדי לממש את התור. כעת, גם אם המערכת נפלה – כל המשימות (מסרים) שהיו בה נשמרו, וברגע שהמערכת תעלה מחדש, היא תמשיך בדיוק מהנקודה בה היא הפסיקה.
- האם כל האיזורים זקוקים בדיוק לאותו המידע? ייתכן שכל איזור זקוק אך ורק (או: בעיקר) למידע מקומי, שמקורו בתהליכים אחרים של המערכת באיזור זה. בניה נכונה של בסיס נתונים (למשל: חלוקה למספר בסיסי נתונים איזוריים, או שימוש בטכנולוגיות של Sharding/Partitioning) יכולה להפוך "בעיה" מסוג זה ל"לא בעיה". למשל: מערכת לניהול בתי ספר בארה"ב יכולה להחזיק את כל המידע בבסיס נתונים אחד, אך היא יכולה גם להחזיק את המידע, פיסית, באיזורים גיאוגרפיים שונים. כך, גם אם תהיה תקלת תקשורת בין אזורים שונים, המערכת שבניו-יורק תמשיך לגשת לנתוני בתי הספר בניו-יורק ללא הפרעה, בעוד שהמערכת שבטקסס תעשה את אותו הדבר מול בסיס הנתונים המקומי שלה.
- במערכות מסויימות ייתכן ש"משימה" היא עניין קריטי שיש לבצע בדיוק פעם אחת. במערכות אחרות, "משימה" עשויה להיות בנויה כך שאם היא לא התבצעה תוך זמן מסויים, לא קרה כלום, כיוון שהמנגנון ייצר בכל מקרה משימה נוספת על פי הצורך. למשל: תהליך של תרמוסטט יכול ליצור משימה לתהליך אחר לצורך הנמכת הטמפרטורה או הגברה שלה. כל עוד הטמפרטורה אינה בטווח הנכון, הוא ייצר משימות מתאימות. גם אם משימה הלכה לאיבוד, או לחילופין התבצעה פעמיים – לא קרה כלום. המערכת בנויה כך שזה פשוט לא ישפיע על הפעולה שלה כל עוד לא מדובר באיבוד מסיבי (עיקרון דומה לזה מופעל בפרוטוקולי תקשורת של מדיה שהם unreliable).
השבתה
לעיתים, נסיון התאוששות עלול לגרום לנזק גדול יותר מאשר הכשל עצמו, ולכן הפתרון היחיד הניתן לביצוע יהיה השבתה של המערכת. למשל, במקרים הבאים ייתכן שאם המערכת אינה מתפקדת ב-100%, האפשרות הבטוחה היחידה היא להשבית אותה:
- מערכת מעליות, אשר מזהה כי אחד הסנסורים לוידוא שאין אנשים החוסמים דלת ("עין אלקטרונית") הפסיק להגיב. נסיון "להתגבר" על הכשל עלול להסתיים במעיכת אחד הדיירים… כנראה שמוטב לעצור את הדלת במצב "פתוח" ולחכות לטכנאי (מובן שמצד שני, חשוב ששאר המעליות בבניין תמשכנה לפעול באופן עצמאי).
- טייס אוטומטי שאינו מקבל נתוני GPS בקצב מספק. ניתן לנסות "להתגבר" על התקלה, אבל נראה שבטוח יותר להעביר את הפיקוד לאנשים בתא הטייס (מצד שני, לא היינו רוצים מערכת שבה עצם יכולת השליטה על המנועים מושבתת…)
- מכשיר ניטור רפואי אשר נתקל בבעיה. תלוי, כמובן, בסוג המכשיר, אולם גם במכשיר קריטי, עדיף כנראה להשבית אותו ולהפעיל צופר אזעקה מאשר לנסות להתגבר על הבעיה ולסיים עם קוצב לב שנותן פעימות לא סדירות או מכונת דיאליזה שאינה מבצעת כלל את פעולתה.
השבתה היא כלי קיצוני. יחד עם זאת, היא "ברירת המחדל" לכל כשל קטן – אם לא נתפוס אותו ונטפל בו, סיכוי טוב שהמערכת פשוט תושבת. חשוב מאוד לבחור בכלי זה רק כאשר הוא הדבר הנכון, ולא להגיע אליו בשל חוסר תכנון או קידוד לקוי.
במערכות שאינן קריטיות כמו מנועי מטוס או קוצבי לב, כדאי לעיתים להשתמש במנגנון ההשבתה בכל מקרה של באג מהסוג של "Can't Happen". למשל, אם נתון ש"חייב" להיות בבסיס הנתונים אינו נמצא, או אם קיבלנו ערך מטיפוס לא מתאים למרות שאין במערכת דרך לגיטימית להכניס אותו כאינפוט. במקרים כאלו, משהו מאוד לא טוב קרה. ייתכן שמישהו תקף את המערכת שלנו, או שיש בה כשל מסוג שכלל לא העלינו על דעתנו (זאת, בניגוד לבעיות "לגיטימיות", כמו בעיות תקשורת או אלמנטים של מערכת ההפעלה). אם נסתפק ב-"Alert", לא בטוח שיהיה מי שיטפל בזה, לעומת השבתה, שתקפיץ מיד את כל המערכת. הדברים נכונים עוד יותר בשלבים מוקדמים של מערכת, כאשר היא טרם הבשילה, ונמצאת בשלבי בדיקות או POC.
התרעה על כשלים
למרות שזה נשמע טריוויאלי — אם יש כשל, צריך ליידע מישהו, לא? — התחום הזה הוא אחד המורכבים שיצא לי להיתקל בהם, ובכל חברה ישנה השקעה רבה בנסיון לבצע אותו בדרך הנכונה ביותר למוצר הספציפי. את הדרך הפשוטה ביותר להתריע הזכרנו בעצם בפרק ה"התאוששות": השבתה של המערכת. מערכת מושבתת היא ההתרעה החזקה ביותר שתדרוש טיפול מיידי. אולם, כמובן, זהו מקרה קיצוני מאוד.
הדרך ליצור מנגנון נכון של התרעות והודעות על קיומם של כשלים משתנה מאוד מחברה לחברה וממוצר למוצר. בעת הגדרת מנגנון כזה, יש צורך לקחת בחשבון משמעויות שונות, כגון:
- למי ממוענת ההתרעה? התרעה יכולה להיות רלוונטית למשתמש, למנהל, לאיש התמיכה, לאיש הפיתוח או לנמענים אחרים. יש דברים שלא נרצה להראות ללקוח, ויש דברים שסתם יטרידו את איש התמיכה. חשוב למען כל התרעה למקום הנכון.
- איזה מידע נושאת ההתרעה? מנגנונים פשוטים מסתפקים לעיתים בהודעה טקסטואלית. מנגנונים קצת יותר מתוחכמים, מוסיפים "קוד שגיאה". אבל מנגנונים מפותחים יותר יכולים לשאת מידע רלוונטי, כמו כתובות רשת, שמות תהליכים, שם קובץ ומספר שורה, שם משתמש, ערכים מספריים הקשורים לגורם הבעיה, Exception רלוונטי, מצב המערכת וכדומה. מנגנונים כאלו הם מסובכים יותר למימוש, ועוד יותר לתחזוקה – ככל שהמערכת מתקדמת יותר, גם המידע הרלוונטי הופך להיות מורכב יותר. מצד שני, הם נותנים הרבה יותר מידע לאנשי התמיכה או אבטחת האיכות; הם מאפשרים שמירה יעילה לבסיסי נתונים בדרך שתאפשר לאחר מכן ניתוח מעמיק; ויותר מכך, הם מאפשרים למערכות תוכנה אחרות להגיב להם או לפעול על פיהם ביתר קלות.
- "עוצמת" ההתרעה – האם מדובר במידע, באזהרה, בשגיאה, בכשל? הגדרה לא נכונה של רכיב זה יכולה להפוך לחלוטין את יעילות מנגנון ההתרעה.
- "מצב" ההתרעה – האם מדובר בהודעה שהיתה נכונה לאותו רגע (למשל: נסיון תקשורת נכשל; תהליך נפל) או בהודעה שעדיין תקפה, ויש צורך לטפל בה (למשל: לא קיימת תקשורת – יש לוודא חיבור פיסי; תהליך אינו רץ – יש להריץ אותו מחדש).
- תדירות ההתרעה – מערכת נאיבית תשלח בכל פעם את אותה ההתרעה עבור אותו כשל. אולם, לעתים רבות המשמעות של הצטברות כשלים היא שיש בעיה חמורה בהרבה. למשל, נסיון גישה לבסיס נתונים שנכשל, הוא מקרה לגיטימי שמערכת סבירה תתמודד איתו בקלות. אולם, אם נסיונות רבים נכשלים, מדובר כנראה בבעיה אקוטית יותר. האם מדובר בכשל של כל נסיון, או אולי רק במחצית מהנסיונות? האם מדובר בכשל גישה לכל רשומה בבסיס הנתונים, או אולי אך ורק לטבלה מסויימת? ניתוח נכון של הכשלים יכול לייצר סט של "התרעות-על", שהן מורכבות יותר לזיהוי, אך עשויות להיות חשובות לאין ערוך מהתרעות "פשוטות". התרעות-על אלו ניתן לייצר ברמת המערכת עצמה, אך ניתן גם לייצר אותן באופן נפרד לחלוטין — למשל, באמצעות תהליך הסורק את רשימת ההתרעות בשעות האחרונות ומחפש בהן חזרות ותבניות.
סיכום
ישנן דרכים רבות בהן ניתן לפעול כדי להפוך מערכת לחסינה בפני כשלים ככל האפשר. הדיאגרמה הבאה מסכמת את הנקודות שהועלו בפוסט:
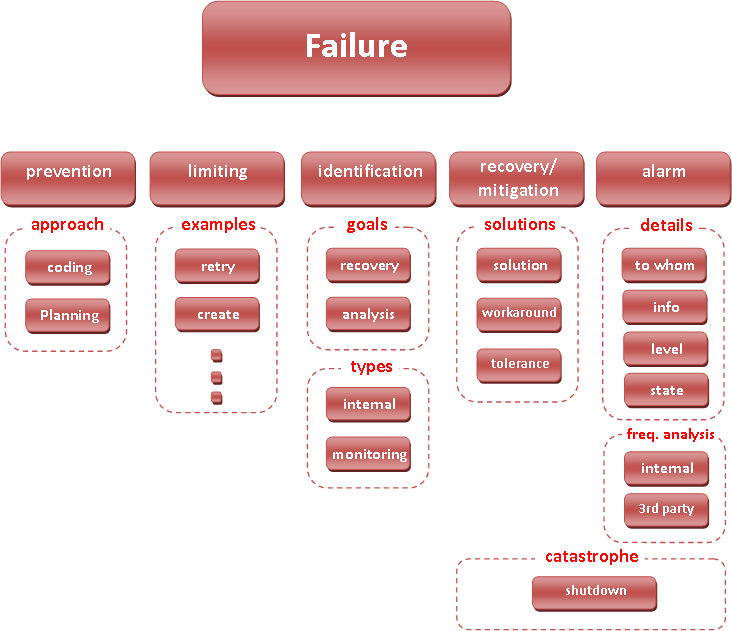
מערך מלא של התמודדות עם כשלים יכלול פתרונות ברמות שונות, אשר יחד, ייצרו כיסוי שלם. מובן שהנקודות המופיעות כאן הן רק ממבט על, ומכסות את הנושאים החשובים מצד התכנון. לא מופיעים כאן, למשל, אלמנטים הקשורים בבדיקות (החל מ-static code analysis ועד למערך QA…) מכיוון שהם נושא בפני עצמם, אולם ברור שבדיקות הן גורם מכריע ביכולת להוציא מוצר ללא כשלים. הנקודות אשר כיסינו כאן נוגעות לרבדים הבאים:
- ברמת הקידוד:
- נהלי קידוד אחידים וברורים ותהליכי Code Review שיוודאו את מימושם
- ברמת הארכיטקטורה:
- ביזור משימות ואלמנטים
- מנגנוני Watchdog
- תכנון טולרנטי
- ברמת המשאבים (כוח עיבוד, נפח זכרון ושמירה, ערוצי תקשורת, הגדרות מערכת ההפעלה):
- הקצאה
- הגדרת ספים קריטיים
- ניטור
- ברמת ההתרעות:
- זיהוי מדוייק ומיידי של כשלים ומצבים קריטיים
- ניתוח של כשלים והתרעות לכדי "התרעות-על"
- ברמת המערך:
- מנגנוני התאוששות אוטומטיים במקומות בהם זה אפשרי
- מערך תמיכה אנושי לטיפול בשאר התחומים
[…] הפוסט פורסם לראשונה בבלוג ״ארכיטקט בכפכפים״. […]
[…] הפוסט פורסם לראשונה בבלוג ״ארכיטקט בכפכפים״. […]
[…] בפוסט הקודם דיברתי על כשלים במערכות תוכנה ברמות השונות. בפוסט הזה, אני מתמקד ברמת הנדסת התוכנה והקידוד עצמו. […]