
I set out to write a post about common design mistakes in RT/Embedded systems, but realized there’s some background—notions not every developer knows, sometimes not even every real-time developer—that’s worth laying first. So I decided to start with a short primer on a broader topic that’s no less interesting, and crucial for anyone building Hard Real-Time systems.
Task Scheduling
One of the most important jobs of any operating system—arguably the most important—is scheduling tasks.
In the most basic systems, as in some real-time OSs, there’s a small number of “tasks” the OS must choose from at any given moment. In more complex OSs, like the ones on our personal computers, there’s a wider set of entities: processes, threads, and others such as services or daemons. Every task, process, or other entity has a priority that indicates how important it is to give it CPU time relative to the rest. That statement is true for almost every OS; but what does “importance” actually mean in practice?
Here, the answer varies quite a bit by the nature and goals of the operating system.
General-Purpose Operating Systems
The mainstream OSs we know—Windows, Linux, and macOS—need to support an open-ended variety of applications and capabilities. Some are part of the OS itself; others are user-facing apps. Some patiently wait for a click; others are resource-hungry and never stop (think games). In the background you can have compute/analytics jobs, services that wait for or initiate network I/O, and drivers talking to your display, mouse, or printer.
An OS like this must be efficient and flexible. It must not let any one entity starve forever. It should utilize resources well. It must stay interactive. And it has to satisfy a long list of other constraints. These systems divide CPU time across runnable entities in a way that gives a reasonable generic outcome across many scenarios.
Typically, you can set a process’s priority and the scheduler will favor it (or the opposite—depending on the priority you choose) within the overall time-sharing algorithm. There are many knobs for how time is divided. But at the end of the day it’s hard—to impossible—to guarantee that a given function will run the instant it’s needed and finish within a strict, bounded interval. If your app only needs to react “within a second,” that’s fine. If it needs “within a millisecond,” that’s already trickier. Sometimes much trickier.
Preemptive Scheduling
In systems that demand immediate, bounded response—Hard RT—generic time-sharing isn’t an option. In these systems, priority must have an absolute meaning: if a high-priority task needs to run at a certain moment, it gets the CPU immediately at that moment. The task currently on the CPU is stopped right away and yields to the higher-priority one. That’s preemptive scheduling. With it, you can guarantee bounded latency for high-priority tasks. On the flip side, there’s no free lunch: adopting this model introduces its own classes of problems.
Throughput Penalties
Systems with lower latency usually deliver lower overall throughput. That’s not always intuitive, and many people conflate the two. For example, when you need to do a lot of computation in a short time, there’s a tendency to think you need “more real-time.” Often the opposite is true.
A preemptive system can guarantee certain operations—usually short ones—finish within a known bound; but the way it achieves this is by performing far more context switches, including at code points where that cost is high. Each context switch forces extra work on the CPU and memory hierarchy, evicts hot cache lines, and so on. A task that runs exclusively and busy-waits for events without releasing the CPU wastes valuable cycles. Net: such a system often limits throughput compared to more sophisticated, flexible time-sharing. If you need sustained number-crunching and you’re not sensitive to a millisecond here or there, a non-preemptive (or more cooperative) OS will almost certainly deliver better throughput.
Starvation
In general-purpose OSs it’s hard to get true starvation: the scheduler ensures every runnable entity gets CPU time, even at a very low priority level. In preemptive systems (and in some similar configurations without full preemption), priority is absolute: a higher-priority task will preempt anything else and run without limit. It yields only when it blocks/finishes, or if an even higher-priority task preempts it.
The difference between “a slow thread” and “a starved thread” is dramatic—especially if the starved one only needs to do a tiny bit of work occasionally (read a value, send a keep-alive), and even more so if it’s momentarily holding a critical resource and therefore can’t release it.
Priority Inversion
Priority inversion is a special case that stems from the phenomenon above.
Suppose we have three tasks:
A with priority 10 (high), B with priority 6 (medium), and C with priority 2 (low).
We expect that whenever A needs to run, it preempts the current task and does its work. B runs only once A has nothing to do. C runs only when neither A nor B need the CPU.
Now imagine C is running and, as part of its work, it takes a shared resource—for example, locks a mutex. Then (say due to an interrupt or a message) B becomes ready. The OS preempts C and runs B. While B is running, A wakes up. The CPU preempts B and runs A. To complete its job, A also needs that mutex; it tries to take it, but it’s locked by C, so A blocks. The scheduler now lets B run, while C is starved; as long as B keeps running, C can’t resume to release the Mutex.

In effect, the medium-priority B is starving not only the low-priority C, but also the high-priority A that’s stuck waiting on C’s locked Mutex. Only after B eventually yields can C run, release the mutex, and then A can continue. A high-priority task (A) being forced to wait behind a lower-priority task (B) is priority inversion. The more complex the system and the more shared-resource dependencies it has, the more likely this becomes.
Priority Inheritance
One way preemptive RTOSs mitigate priority inversion is priority inheritance.
Back to our scenario: C locked the mutex; A needs it and is blocked; B (medium) is currently running and, in practice, outranks A. In a system with priority inheritance, when A tries to take the locked Mutex, the OS recognizes the situation and temporarily raises C’s priority to A’s level. As a result, when A blocks, B does not continue; C runs instead (now at high priority), does just enough work to release the mutex, then its priority drops back to its original low value. At that point A resumes and B waits. This prevents the inversion.
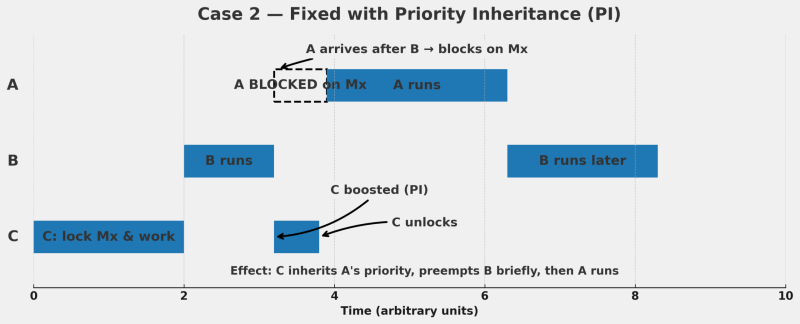
Most modern RTOSs implement some form of priority inheritance, but the scenarios aren’t always simple and the solutions are relatively complex for typically “thin” kernels. There may be have dependency chains (for example, C is also blocked on a resource held by D), and not every resource is strictly two-party; some involve more than two tasks.
So it’s important to avoid designs that make inversion likely, because the OS won’t always save you. For example, in FreeRTOS the inheritance mechanism applies when the shared resource is a mutex, but it does not kick in for other primitives such as a binary semaphore. In addition, the mechanism isn’t perfectly tight; to keep the implementation simple, priority changes may not always occur at the exact optimal moment.
Understanding the Scheduler
Scheduler internals aren’t everyone’s favorite topic, but for people writing code on real-time systems—Hard RT or Soft RT—they’re critical. There are, of course, many more aspects of task scheduling, but the ones above are foundational. Misunderstanding them is a good way to make a system fail exactly where it can’t afford to.
This is the groundwork for more advanced topics I’ll cover in the next posts.